自从很多关于python爬虫的文章被下架了后,我的博文是越来越没起色了。我想是因为账号的权重被下降的太多了。如果文章对您有所帮助,我希望大家可以帮忙点个一键三连,顺便动动您发财的小手给我来个如实的评论。


关于这个脚本的话,其实是我18年给学员讲的一个小案例。虽然是针对淘宝的,但实际上它是个万能脚本,为什么呢?因为它是selenium写的,所以说基本都是通用的,无非是改一些元素选择即可。
本文包含文章的思路介绍以及源代码提供,并且包含视频教程!
分析(x0)
私信小编01即可获取大量Python学习资源
首先咱们以淘宝为例,那么你想要抢购商品,
第一步
要做的就是登录账号:
然后呢
第二步
大家一定要选择扫码登录:
理由就是淘宝毕竟是淘宝,你正常的模拟输入账号密码是被检测的,有人可能已经尝试过,我可以这样讲吧,如果把账号拆成三段,密码拆成三段,然后加延迟的话确实偶尔可以登录成功!
但是你要知道为什么是偶尔呢?因为淘宝风控的是你的代理包括你的一个机器环境。所以咱们还是老老实实选择扫码登录吧。
第三步
肯定好多人会认识是搜商品然后…..其实不是的,关于咱们的一个抢购机制咱们一定要明白,那就是以结算为准以结算为准以结算为准,重要的事情说三遍,

何为结算?
其实就是说你只需要点击到结算按钮即可(即使不结算也没事,只要你点击了结算,系统会提醒你必须多长时间内付款,但实际上这个商品只要你付款就已经属于你,名额已经属于你了)
所以咱们需要做的就是提前手动把需要抢购的商品添加到购物车,然后判断时间,如果到点了,那么脚本立马给我无限点击结算即可!

环境配置
模块
- selenium
- time
pip install selenium
time 为内置模块无需安装。
selenium的环境配置
这个东西我讲过无数遍了,没办法 。还是得从以前的文章中复制粘贴过来……
关于selenium这个模块,咱们来重点介绍一下:
Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。
如果不能够理解我就讲点白话,如果你是web开发人员,开发好了几百个网站,那么如果你认为的去一个个的测试BUG,是不是很浪费时间?而selenium这个框架就是用来模拟人去自动化操控浏览器的,那么是不是就节约了很多时间呢。
既然selenium能够操控浏览器,那么它们之间必须要有一个桥梁,总不能无中生有吧?
那么操控的浏览器款式不一样,中间的桥梁也是不一样的。比如我更喜欢用chrome浏览器,那么咱们需要下载一个selenium与Chrome的桥梁——Chromedriver插件
下载地址
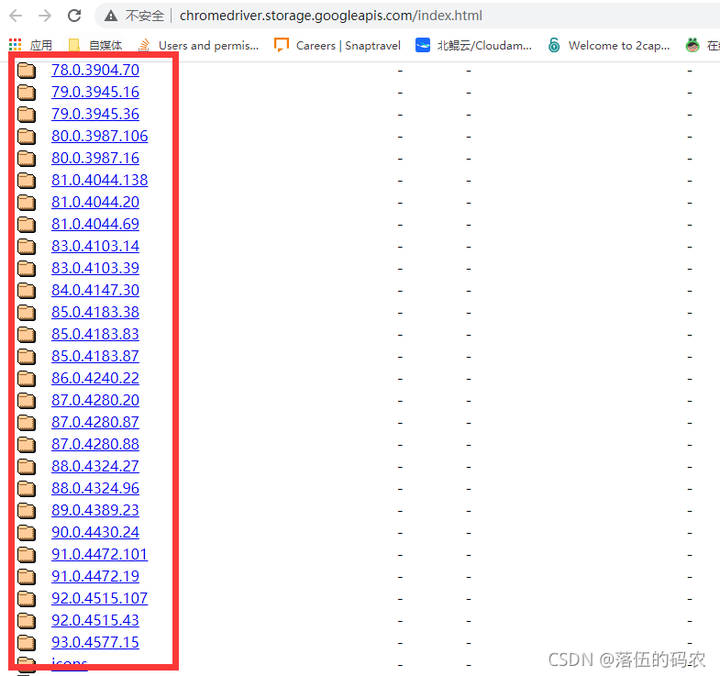
下载与你当前谷歌浏览器版本最相近的Chromedriver
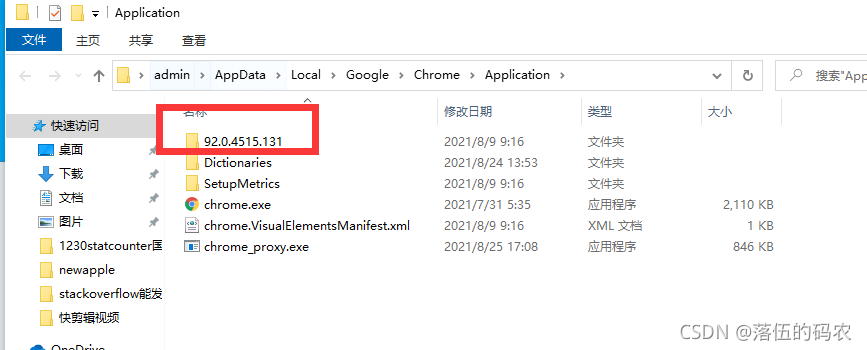
那么像我的话,下载
即可。
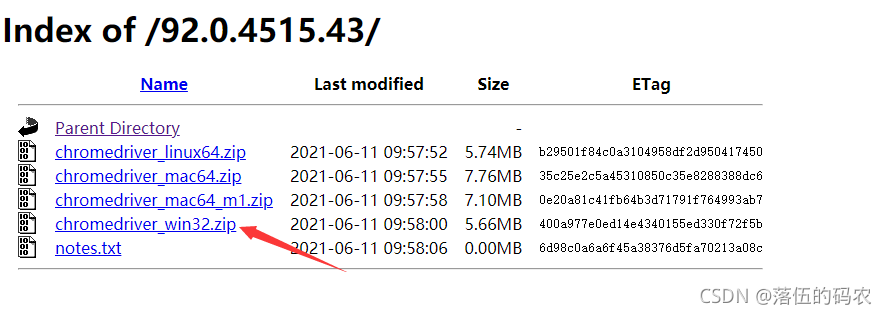
Windows系统需下载32位,其它的自己看着办。点进去下载win32即可。
那么如何让Python与selenium连接起来呢,这里咱们需要配置一个环境变量,就是把Python与selenium处于同一个目录:
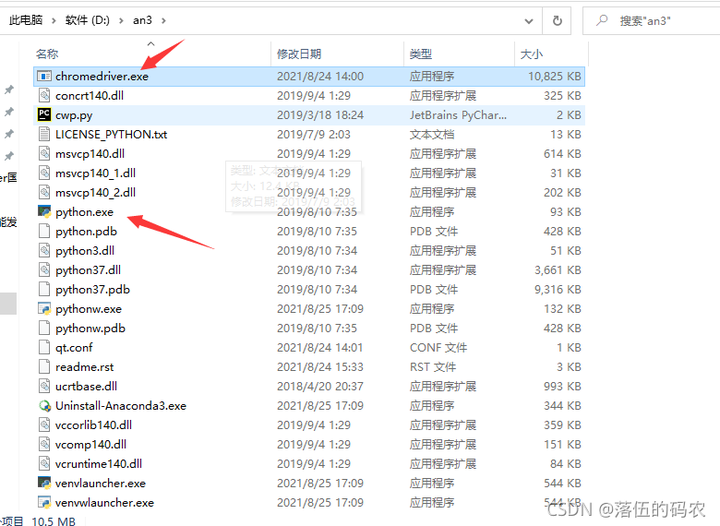
到此为止,咱们的环境就搭建好了。
Python代码
from selenium import webdriverimport datetime, timedef login(): # 打开淘宝登录页,并经行扫码登录 brower.get(“https://www.taobao.com“) # 等待selenium 框架加载网页完成 time.sleep(3) if brower.find_element_by_link_text(“亲,请登录”): brower.find_element_by_link_text(“亲,请登录”).click() input(‘扫码完成后按一下Enter键’) brower.get(“https://cart.taobao.com/cart.htm“) time.sleep(3) now = datetime.datetime.now() print(‘login success: ‘, now.strftime(‘%Y-%m-%d %H:%M:%S’))# 2. 实现商品购买def buy(times): # 点击购物车里的全选按钮 while True: now = datetime.datetime.now().strftime(‘%Y-%m-%d %H:%M:%S.%f’) # 对比时间,时间到的话就点击结算 if now > times: while True: # 异常处理 try: if brower.find_element_by_id(“J_SelectAll2”): brower.find_element_by_id(“J_SelectAll2″).click() break except: print(‘找不到全选按钮…’) # 点击结算按钮//*[@id=”J_Go”]/span while True: try: if brower.find_element_by_xpath(‘//*[@id=”J_Go”]/span’): brower.find_element_by_xpath(‘//*[@id=”J_Go”]/span’).click() print(‘结算成功’) break except: print(‘找不到结算按钮’) # 提交订单 # while True: # try: # if brower.find_element_by_link_text(‘提交订单’): # brower.find_element_by_link_text(“提交订单”).click() # now1 = datetime.datetime.now().strftime(‘%Y-%m-%d %H:%M:%S.%f’) # print(‘抢购成功时间:%s’ % now1) # break # except: # print(‘我的银行卡没钱…’) # # time.sleep(0.01)#2019-06-09 17:05:00.000000# 启动函数2019-11-02 14:03:00.000000if __name__ == “__main__”: times = input(“请输入抢购时间,格式(2019-05-08 20:00:00.000000):”) brower = webdriver.Chrome() login() buy(times)
 微信扫一扫
微信扫一扫